csapp arch_lab
csapp lab arch_lab
初见arch lab
In this lab, you will learn about the design and implementation of a pipelined Y86-64 processor, optimizing both it and a benchmark program to maximize performance. You are allowed to make any semanticspreserving transformation to the benchmark program, or to make enhancements to the pipelined processor, or both. When you have completed the lab, you will have a keen appreciation for the interactions between code and hardware that affect the performance of your programs.
The lab is organized into three parts, each with its own handin. In Part A you will write some simple Y86-64 programs and become familiar with the Y86-64 tools. In Part B, you will extend the SEQ simulator with a new instruction. These two parts will prepare you for Part C, the heart of the lab, where you will optimize the Y86-64 benchmark program and the processor design.
Part A
这一部分主要使用Y86-64汇编语言改写C语言程序,示例在example.c中。
1 | |
可以看到其给出了链表的数据结构定义
sumlist
第一个程序要求迭代求和链表元素之和,我们的程序应该包括设计栈空间,引用函数,并且停止。同时给出了测试所用的案例。
1 | |
一个简单但标准的Y86-64程序结构可以参考书上的252页。
1 | |
使用yas编译,使用yis模拟运行程序
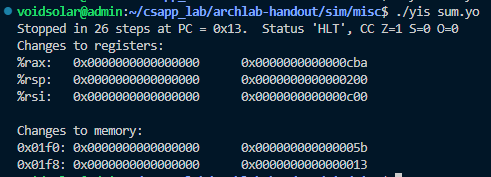
看到rax寄存器中结果为0xcba,程序运行正确。
rsum_list
使用递归计算链表元素之和。
1 | |
代码如下:
1 | |
测试结果如下
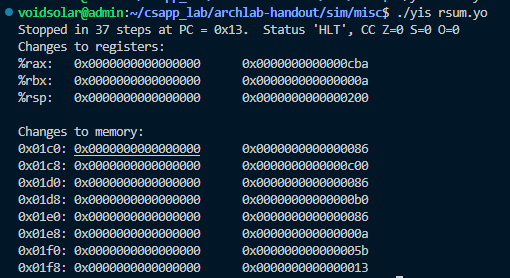
rax寄存器显示0xcba,结果正确。
copy
要求数组各元素的按位异或值
1 | |
1 | |
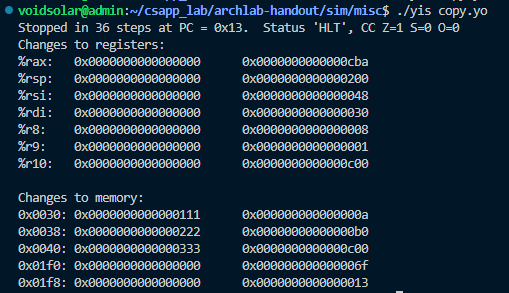
结果正确
Part B
to extend the SEQ processor to support the iaddq,
让处理器支持iaddq指令,修改hcl文件。
书中P264Y86-64处理器对一条指令的处理包括以下几个步骤:
- 取址:根据 PC 的值从内存中读取指令字节
- 指令指示符字节的两个四位部分,为
icode:ifun - 寄存器指示符字节,为
rA,rB - 8字节常数字,为
valC - 计算下一条指令地址,为
valP
- 指令指示符字节的两个四位部分,为
- 译码:从寄存器读入最多两个操作数
- 由
rA,rB指明的寄存器,读为valA,valB - 对于指令
popq,pushq,call,ret也可能从%rsp中读
- 由
- 执行:根据
ifun计算,或计算内存引用的有效地址,或增加或减少栈指针- 对上述三者之一进行的操作得到的值为
valE - 如果是计算,则设置条件码
- 对于条件传送指令,检验条件码和传送条件,并据此更新目标寄存器
- 对于跳转指令,决定是否选择分支
- 对上述三者之一进行的操作得到的值为
- 访存:输入写入内存或从内存读出数据
- 若是从内存中读出数据,则读出的值为
valM
- 若是从内存中读出数据,则读出的值为
- 写回:最多写两个结果到寄存器
- 更新 PC:将 PC 设置成下一条指令的地址
其执行过程与OPq和irmovq类似,
1 | |
根据上述代码修改hcl文件,
其中取值阶段instr_valid need_regids need_valC需要加上iiaddq
1 | |
1 | |
1 | |
译码和写回 srcB(产生valB)的寄存器,需要在rB的括号中加上iiaddq
1 | |
dst_E表明写端口 E 的目的寄存器,计算出来的值valE将放在那里。最终结果要存放在rB中,需要在rB的前面加上iiaddq
1 | |
执行阶段ALU对aluA和aluB进行计算,aluA可以是valA、valC 、8或-8,aluB只能是valB
1 | |
同时需要更新条件码寄存器
1 | |
iiaddq不涉及访存和转移操作,无修改访存阶段和更新PC阶段。
使用lab附的SEQ模拟器的TTY模式对HCL文件进行测试。(同时也建议大家去看看GUI模式,很惊艳
1 | |
基准测试
运行基准测试保证指令集原有指令没有被破坏
1 | |
回归测试
测试除了iaddq以外的指令
1 | |
测试自己实现的iaddq
1 | |
至此Part B全部完成
Part C
我们需要修改HCL和ncopy来优化程序,通过程序的效率计算分数
首先iaddq是一条效率很高的指令,它能够将两步化为一步。
1 | |
原汇编代码如下:
1 | |
利用iaddq替换原有的赋值指令。替换后
1 | |
根据文档的提示,我们尝试使用循环展开对程序进行优化,循环展开通过增加每次迭代计算的元素的数量,减少循环的迭代次数来提升效率。
本文在参考了别人的博文的基础上使用6路循环展开
1 | |
逻辑简单:每次循环都对6个数进行复制,每次复制就设置一个条件语句判断返回时是否加1,对于剩下的数据每次循环只对1个数进行复制。
此时测试发现对于小数据的CPE值非常大,需要考虑对小数据进行优化。
于是对剩余数据采取3路循环展开。
1 | |
消除气泡
程序多次使用
1 | |
使用转发避免数据冒险,也至少会有一个气泡。
另外一种优化方法是多取一个寄存器,连续进行两次数据复制
1 | |
源程序如下
1 | |
1 | |
总结
- csapp第四章对于我来讲太难了,但在自己亲手设计指令的过程中能模拟流水线的工作流程并尝试优化,让我这个noob得以一窥处理器体系结构的冰山一角。
- 本lab同之前的lab一样,诚意满满,yas、yis、ssim、psim等模拟、测试工具一应俱全,整个过程如同游戏闯关一样令人着迷。