In Part A you will write a cache simulator in csim.c that takes a valgrind memory trace as input, simulates the hit/miss behavior of a cache memory on this trace, and outputs the total number of hits, misses, and evictions.
要求编写cache模拟器,模拟cache在这个trace的hit/miss表现,并输出hit miss evictions的总数
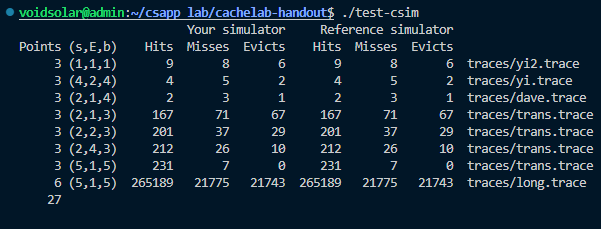
lab给出了可供参考的cache模拟器,其有以下六个参数
1 2 3 4 5 6 7
Usage: ./csim-ref [-hv] -s <s> -E <E> -b<b> -t <tracefile> • -h: Optional help flag that prints usage info • -v: Optional verbose flag that displays trace info • -s <s>: Number of setindex bits (S = 2^s is the number of sets) • -E <E>: Associativity (number of lines per set) • -b<b>: Number of block bits (B = 2^bis the block size) • -t <tracefile>: Name of the valgrind trace to replay
trace文件夹包含了用于评估模拟器的trace文件,其使用valgrind生成
trace文件中具体定义为
1 2 3 4
I0400d7d4,8 M0421c7f0,4 L04f6b868,8 S7ff0005c8,8
其具体格式为
1
[space]operation address,size
The operation field denotes the type of memory access: “I” denotes an instruction load, “L” a data load, “S” a data store, and “M” a data modify (i.e., a data load followed by a data store). There is never a space before each “I”. There is always a space before each “M”, “L”, and “S”. The address field specifies a 64-bit hexadecimal memory address. The size field specifies the number of bytes accessed by the operation.
4种operation
I 表示加载指令 其之前不加[space]
L表示加载数据
S表示存储数据
M表示修改数据
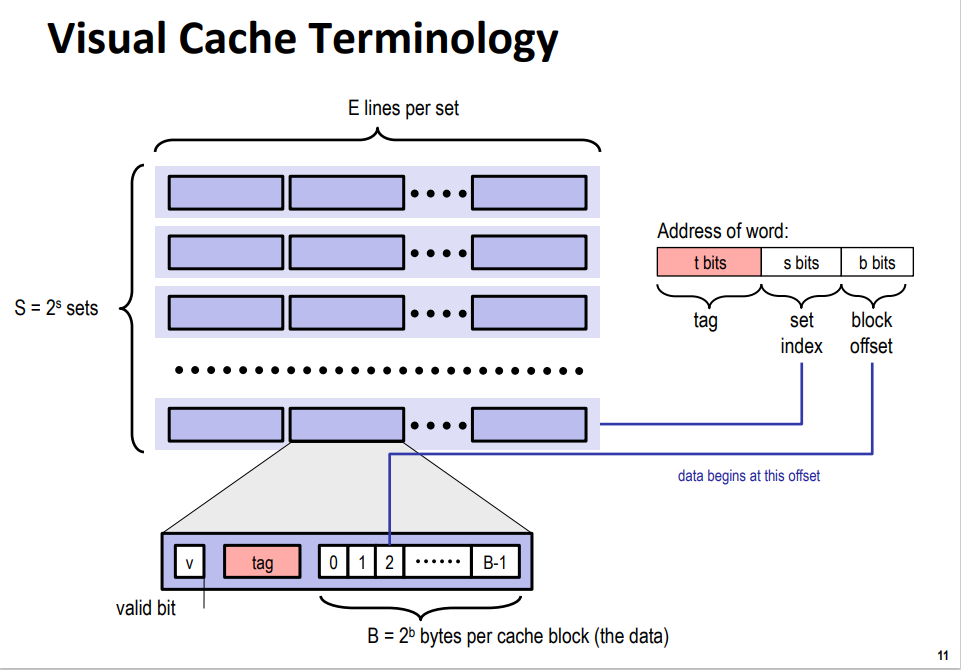
回顾cache结构
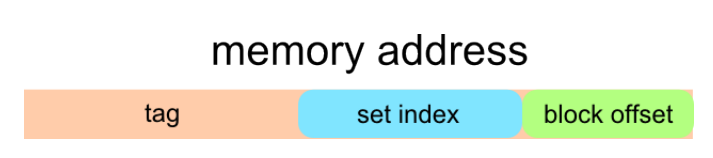
Cache 类似于一个二维数组,它有 S=2^s 组,每组有 E 行,每行存储的字节也是固定的。其中,每行都有一个有效位,和一个标记位。想要查找到对应的字节,我们的地址需要三部分组成:
voidInit_Cache(int s, int E, int b) { int S = 1 << s; int B = 1 << b; cache = (Cache *)malloc(sizeof(Cache)); cache->S = S; cache->E = E; cache->B = B; cache->line = (Cache_line **)malloc(sizeof(Cache_line *) * S); for (int i = 0; i < S; i++) { cache->line[i] = (Cache_line *)malloc(sizeof(Cache_line) * E); for (int j = 0; j < E; j++) { cache->line[i][j].valid = 0; cache->line[i][j].tag = -1; cache->line[i][j].time_tamp = 0; } } }
时间戳的初始设置为0
LRU时间戳实现
时间戳越大则表示该行最后访问的时间越久远,
1 2 3 4 5 6 7 8
voidupdate(int i, int op_s, int op_tag){ cache->line[op_s][i].valid=1; cache->line[op_s][i].tag = op_tag; for(int k = 0; k < cache->E; k++) if(cache->line[op_s][k].valid==1) cache->line[op_s][k].time_tamp++; cache->line[op_s][i].time_tamp = 0; }
intmain(int argc, char *argv[]) { char opt; int s, E, b; /* * s:S=2^s是组的个数 * E:每组中有多少行 * b:B=2^b每个缓冲块的字节数 */ while (-1 != (opt = getopt(argc, argv, "hvs:E:b:t:"))) { switch (opt) { case'h': print_help(); exit(0); case'v': verbose = 1; break; case's': s = atoi(optarg); break; case'E': E = atoi(optarg); break; case'b': b = atoi(optarg); break; case't': strcpy(t, optarg); break; default: print_help(); exit(-1); } } Init_Cache(s, E, b); //初始化一个cache get_trace(s, E, b); free_Cache(); // printSummary(hit_count, miss_count, eviction_count) printSummary(hit_count, miss_count, eviction_count); return0; }
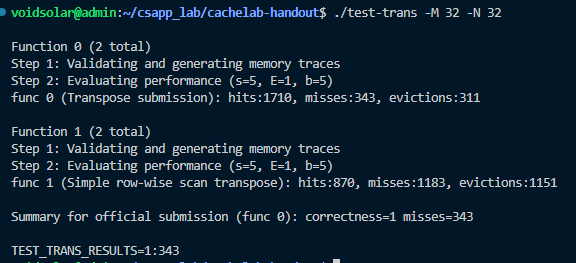
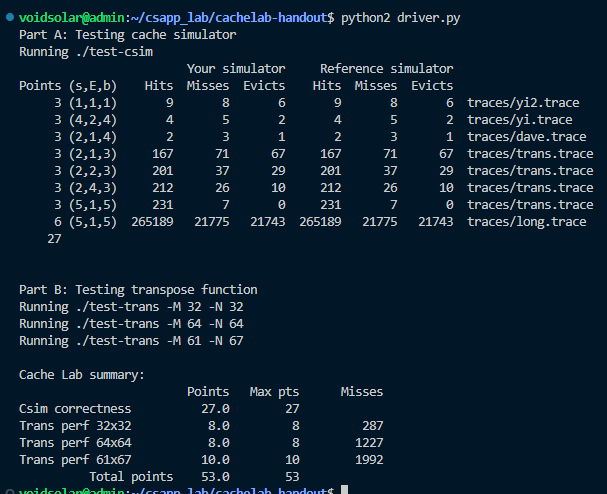
Part B: Optimizing Matrix Transpose
In Part B you will write a transpose function in trans.c that causes as few cache misses as possible.
要求本地变量最多定义12个
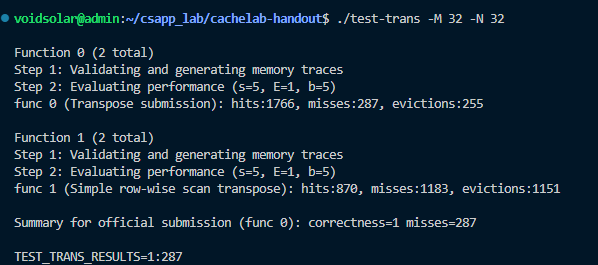
32 × 32: 8 points if m < 300, 0 points if m > 600
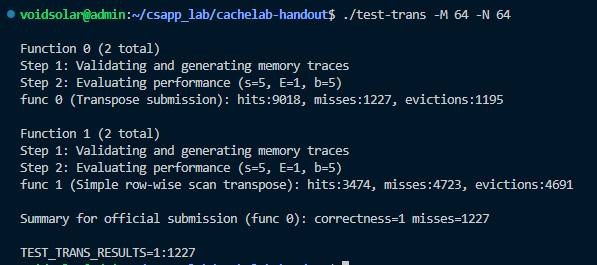
64 × 64: 8 points if m < 1, 300, 0 points if m > 2, 000
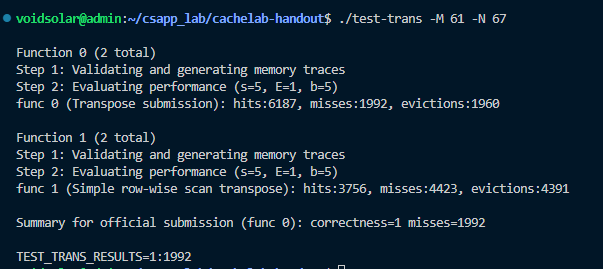
61 × 67: 10 points if m < 2, 000, 0 points if m > 3, 000
s = 5, E = 1, b = 5,缓存有32组,每组一行,一行存8个int
32*32
根据pdf的提示,这里肯定要使用矩阵分块进行优化
首先考虑最最简单的转置情况
1 2 3 4 5 6 7 8
voidtrans_submit(int M, int N, int A[N][M], int B[M][N]) { for (int i = 0; i < N; i++) { for (int j = 0; j < M; j++) { int tmp = A[i][j]; B[j][i] = tmp; } } }
voidtranspose_submit(int M, int N, int A[N][M], int B[M][N]) { for (int i = 0; i < N; i += 8) for (int j = 0; j < M; j += 8) for (int k = 0; k < 8; k++) for (int s = 0; s < 8; s++) B[j + s][i + k] = A[i + k][j + s]; }
voidtranspose_submit(int M, int N, int A[N][M], int B[M][N]) { for(int i = 0; i < 32; i += 8) for(int j = 0; j < 32; j += 8) for (int k = i; k < i + 8; k++) { int a_0 = A[k][j]; int a_1 = A[k][j+1]; int a_2 = A[k][j+2]; int a_3 = A[k][j+3]; int a_4 = A[k][j+4]; int a_5 = A[k][j+5]; int a_6 = A[k][j+6]; int a_7 = A[k][j+7]; B[j][k] = a_0; B[j+1][k] = a_1; B[j+2][k] = a_2; B[j+3][k] = a_3; B[j+4][k] = a_4; B[j+5][k] = a_5; B[j+6][k] = a_6; B[j+7][k] = a_7; } }
void transpose_61x67(int M, intN, int A[N][M], int B[M][N]){ for (int i = 0; i < N; i += 16) for (int j = 0; j < M; j += 16) for (int k = i; k < i + 16 && k < N; k++) for (int s = j; s < j + 16 && s < M; s++) B[s][k] = A[k][s]; }