Malloc Lab Writing a Dynamic Storage Allocator动态存储分配器
Introduction In this lab you will be writing a dynamic storage allocator for C programs, i.e., your own version of the malloc, free and realloc routines. You are encouraged to explore the design space creatively and implement an allocator that is correct, efficient and fast.
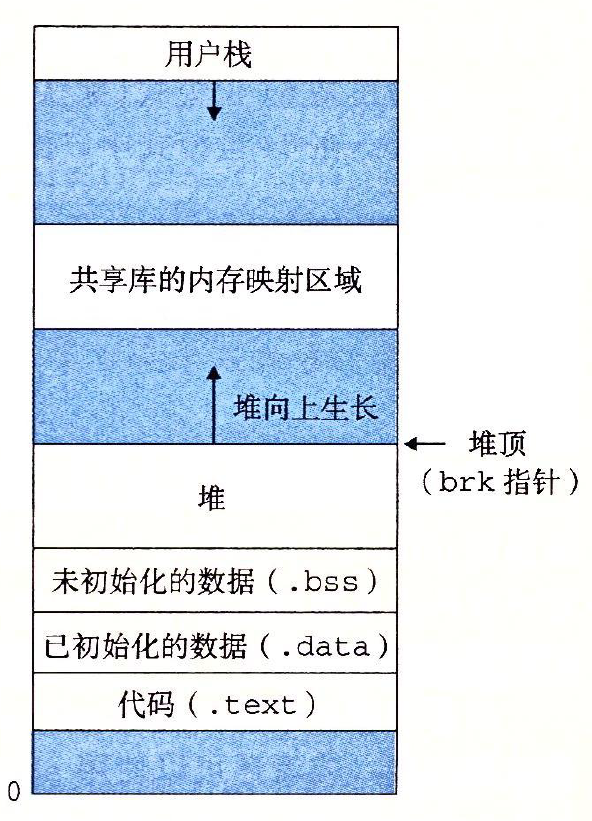
思路 动态内存分配器维护着一个进程的虚拟内存 区域,称为堆。如图:
分配器将堆视为一组大小不同的块的集合来维护,且它们的地址是连续的。将块标记为两种,已分配的块供应用程序使用,空闲块用来分配,
如何组织这些块,课本提供了三种实现方式
Implicit Free List 把所有的块连接起来,每次分配的时从头到尾扫描合适的空闲块
Explicit Free List 是Implicit Free List的进一步优化,每个链表中的块有大致相等的大小,分配器维护着一个空闲链表数组,每个大小类一个空闲链表,但需要分配块时只需要在对应的空闲链表中搜索就好,书中有两种分离存储的方式。
Simple Segregated Storage 从不合并与分离,每个块的大小就是大小类中最大元素的大小。例如大小类为 {17~32},则需要分配块的大小在这个区间时均在此对应链表进行分配,并且都是分配大小为 32 的块。这样做,显然分配和释放都是常数级的,但是空间利用率较低
Segregated Fit 每个大小类的空闲链表包含大小不同的块,分配完一个块后,将这个块进行分割,并根据剩下的块的大小将其插入到适当大小类的空闲链表中。这个做法平衡了搜索时间与空间利用率,C 标准库提供的 GNU malloc 包就是采用的这种方法。
Implicit Free List实现 立即边界合并方式实现
要想分数尽可能高,我们需要使吞吐率尽可能高,空间利用率尽可能小,如果从不重复利用任何块,函数的吞吐率会非常好,而空间利用率会很差;而若进行空闲块的分割合并等操作又会影响吞吐率,因而,就要设计合适的数据结构与算法来平衡两者的关系。
空闲块组织:利用隐式空闲链表记录空闲块
放置策略:如何选择合适的空闲块分配?
首次适配:从头开始搜索空闲链表,选择第一个合适的空闲块
下一次适配:从上一次查询结束的地方开始搜索选择第一个合适的空闲块
最佳适配:搜索能放下请求大小的最小空闲块
分割:在将一个新分配的块放置到某个空闲块后,剩余的部分要进行处理
合并:释放某个块后,要让它与相邻的空闲块合并
空闲块组织:
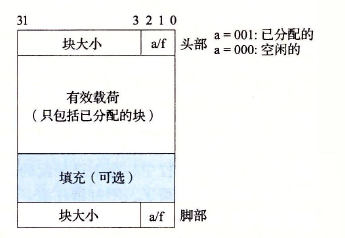
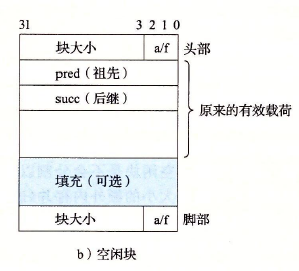
脚部与头部是相同的,均为 4 个字节,用来存储块的大小,以及表明这个块是已分配还是空闲块
由于要求块双字对齐,所以块大小就总是 8 的倍数,低 3 位总是为 0,因而,我们只需要利用头部和脚部的高 29 位存储块的大小,剩下 3 位的最低位来指明这个块是否空闲,000 为空闲,001 为已分配
为什么既设置头部又设置尾部呢?这是为了能够以常数时间来进行块的合并。无论是与下一块还是与上一块合并,都可以通过他们的头部或尾部得知块大小,从而定位整个块,避免了从头遍历链表。
堆有两个特殊的标记:
序言块:8 个字节,由一个头部和一个脚部组成
结尾块:大小为 0 的头部
为了消除合并空闲块时边界的考虑,将序言块和结尾块的分配位均设置为已分配。为了保证双字对齐,在序言块的前面还设置了 4 个字节作为填充。
根据上述结构,可以定义一些方便操作的宏:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #define WSIZE 4 #define DSIZE 8 #define CHUNKSIZE (1 << 12) #define PACK(size, alloc) ((size) | (alloc)) #define GET(p) (*(unsigned int *)(p)) #define PUT(p, val) ((*(unsigned int *)(p)) = (val)) #define GET_SIZE(p) (GET(p) & ~0x7) #define GET_ALLOC(p) (GET(p) & 0x1) #define HDRP(bp) ((char*)(bp) - WSIZE) #define FTRP(bp) ((char*)(bp) + GET_SIZE(HDRP(bp)) - DSIZE) #define NEXT_BLKP(bp) ((char*)(bp) + GET_SIZE(((char*)(bp) - WSIZE))) #define PREV_BLKP(bp) ((char*)(bp) - GET_SIZE(((char*)(bp) - DSIZE)))
合并与分割 先初始化堆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int mm_init (void ) if ((heap_list = mem_sbrk(4 *WSIZE)) == (void *)-1 )return -1 ;0 ); 1 *WSIZE), PACK(DSIZE, 1 )); 2 *WSIZE), PACK(DSIZE, 1 )); 3 *WSIZE), PACK(0 , 1 )); 2 *WSIZE);if (extend_heap(CHUNKSIZE/WSIZE) == NULL )return -1 ;return 0 ;
重点在于扩展堆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void *extend_heap (size_t words) char *bp;size_t size;2 ) ? (words+1 ) * WSIZE : words * WSIZE;if ((long )(bp = mem_sbrk(size)) == -1 )return NULL ;0 )); 0 )); 0 , 1 )); return coalesce(bp);
扩展堆每次在原始堆的尾部申请空间,mem_sbrk函数返回指向旧堆尾部的指针,因此,可以直接将原始堆的尾部位置设置新空闲块的头部。
接下来就是 free ,设置一下头部和脚部即可,free 完后注意合并空闲块
1 2 3 4 5 6 7 8 9 10 11 12 13 void mm_free (void *ptr) if (ptr==0 )return ;size_t size = GET_SIZE(HDRP(ptr));0 ));0 ));
分割空闲块要考虑剩下的空间是否足够放置头部和脚部
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void place (void *bp, size_t asize) size_t csize = GET_SIZE(HDRP(bp));if ((csize - asize) >= 2 *DSIZE) {1 ));1 ));0 ));0 ));else {1 ));1 ));
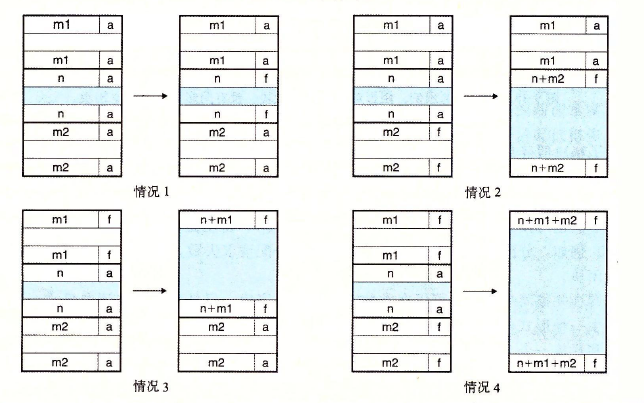
合并 需要考虑四种情况进行处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 void *coalesce (void *bp) size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp))); size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); size_t size = GET_SIZE(HDRP(bp)); if (prev_alloc && next_alloc){return bp;else if (prev_alloc && !next_alloc){0 )); 0 )); else if (!prev_alloc && next_alloc){0 ));0 ));else {0 ));0 ));return bp;
放置策略 首次适配
1 2 3 4 5 6 7 8 9 10 void *find_fit (size_t asize) void *bp;for (bp = heap_list; GET_SIZE(HDRP(bp)) > 0 ; bp = NEXT_BLKP(bp)){if ((GET_SIZE(HDRP(bp)) >= asize) && (!GET_ALLOC(HDRP(bp)))){return bp;return NULL ;
最佳适配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void *best_fit (size_t asize) {void *bp;void *best_bp = NULL ;size_t min_size = 0 ;for (bp = heap_list; GET_SIZE(HDRP(bp)) > 0 ; bp = NEXT_BLKP(bp)){if ((GET_SIZE(HDRP(bp)) >= asize) && (!GET_ALLOC(HDRP(bp)))){if (min_size ==0 || min_size > GET_SIZE(HDRP(bp))){return best_bp;
分配块
最后就是主体部分 mm_malloc 函数,对申请的空间大小按 8 对齐进行舍入,然后根据放置策略查找有无合适的空闲块,如果没有则申请扩展堆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void *mm_malloc (size_t size) size_t asize;size_t extendsize;char *bp;if (size == 0 )return NULL ;if (size <= DSIZE)2 *DSIZE;else -1 )) / DSIZE);if ((bp = best_fit(asize)) != NULL ){return bp;if ((bp = extend_heap(extendsize/WSIZE)) == NULL )return NULL ;return bp;
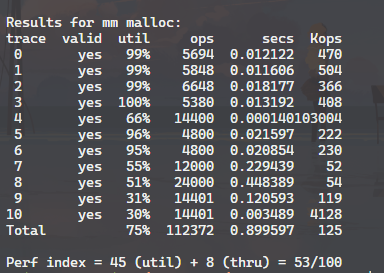
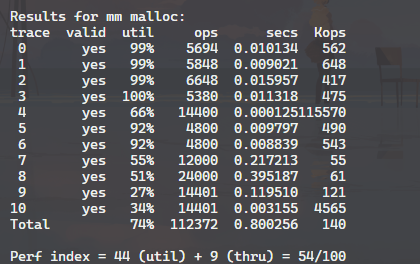
结果与分数 使用最佳适配
使用首次适配
最佳适配的分数反而变低了,原因是虽然空间利用率提高了,但是时间增加太多了。
Segregated Free Lists实现
每个块都有一个头部和脚部,在有效载荷中又分别存放着指向前一个块和后一个块的指针。所以每一个空闲块最小为16字节。
堆的结构也在原来的结构上进行改进
相当于在原来的堆结构中增加了两点:
堆结构的前面放置不同等价类空闲块的头指针
每个空闲块的有效载荷分出一部分作为前驱和后继指针
也就是说,我们的这个做法与 Implicit Free List 非常相似,只不过多维护了 n 个链表
根据链表的结构特点,增加了几个操作宏:
1 2 3 4 5 6 7 #define GET(p) (*(unsigned int *)(p)) #define GET_HEAD(num) ((unsigned int *)(long)(GET(heap_list + WSIZE * num))) #define GET_PRE(bp) ((unsigned int *)(long)(GET(bp))) #define GET_SUC(bp) ((unsigned int *)(long)(GET((unsigned int *)bp + 1)))
大小类设置 由上述结构,每个空闲块最小也要 16 个字节,理论上来说,设置的大小类越多,时间性能要越好,因而设置 20 个大小类:
${16},{17-32},{33-64},…,{2049-4096},{4097-9194},…,{2^{22}+1-\infty}$
结构建立 先看初始化函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int mm_init (void ) if ((heap_list = mem_sbrk((4 +CLASS_SIZE)*WSIZE)) == (void *)-1 )return -1 ;for (int i = 0 ; i < CLASS_SIZE; i++){NULL );0 );1 + CLASS_SIZE)*WSIZE), PACK(DSIZE, 1 )); 2 + CLASS_SIZE)*WSIZE), PACK(DSIZE, 1 )); 3 + CLASS_SIZE)*WSIZE), PACK(0 , 1 )); if (extend_heap(CHUNKSIZE/WSIZE) == NULL )return -1 ;return 0 ;
在序言块之前放置 20 个空闲链表头指针,剩下的结构与原来完全一样。而扩展堆是在结尾块后进行扩展,因而扩展块操作也与原来相同
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void *extend_heap (size_t words) char *bp;size_t size;2 ) ? (words+1 ) * WSIZE : words * WSIZE;if ((long )(bp = mem_sbrk(size)) == -1 )return NULL ;0 )); 0 )); 0 , 1 )); return coalesce(bp);
维护链表 在知道要请求块的大小后,我们要先根据大小定位到相应大小类的头结点:
1 2 3 4 5 6 7 8 9 10 11 12 int search (size_t size) int i;for (i = 4 ; i <=22 ; i++){if (size <= (1 << i))return i-4 ;return i-4 ;
注意,头结点位置下标是从 0 开始,所以返回i-4。这里还可以写一个二分查找的形式,但是优化作用不大。
找到头结点后,就涉及到双向链表的插入和删除了,下面编写这两个函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void insert (void *bp) size_t size = GET_SIZE(HDRP(bp));int num = search(size);if (GET_HEAD(num) == NULL ){NULL );unsigned int *)bp + 1 , NULL );else {unsigned int *)bp + 1 , GET_HEAD(num));NULL );
这个函数还是比较容易编写的,主要是要注意以下几点:
插入块总是插入到表头
指针问题要细致考虑。比如:heap_list + WSIZE * num是对应大小类头结点在堆中的位置,而GET_HEAD(num)是大小类头结点存放的第一个块的地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 void delete (void *bp) size_t size = GET_SIZE(HDRP(bp));int num = search(size);if (GET_PRE(bp) == NULL && GET_SUC(bp) == NULL ) { NULL );else if (GET_PRE(bp) != NULL && GET_SUC(bp) == NULL ) {1 , NULL );else if (GET_SUC(bp) != NULL && GET_PRE(bp) == NULL ){NULL );else if (GET_SUC(bp) != NULL && GET_PRE(bp) != NULL ) {1 , GET_SUC(bp));
同样要注意指针的问题。比如:GET_PRE(bp) + 1是bp指向的块的前驱的后继的位置 ;而GET_PRE(bp+1)是bp指向的块的后继。我在这里因为 segmentation fault 卡了好久。
合并与分割 合并操作还是与 Implict Free List 一样,是根据空闲块在堆中位置相邻来合并的,与链表排列无关
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 void *coalesce (void *bp) size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp))); size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); size_t size = GET_SIZE(HDRP(bp)); if (prev_alloc && next_alloc){return bp;else if (prev_alloc && !next_alloc){0 )); 0 )); else if (!prev_alloc && next_alloc){0 ));0 ));else {0 ));0 ));return bp;
操作与 Implict Free List 几乎相同
额外的操作就是合并前要将前后的空闲块从它的原链表中删除,合并完成后要将新的空闲块插入对应的空闲链表中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 void place (void *bp, size_t asize) size_t csize = GET_SIZE(HDRP(bp));if ((csize - asize) >= 2 *DSIZE) {1 ));1 ));0 ));0 ));else {1 ));1 ));
分离空闲块也只是加入了将分离出来的空闲块插入相应空闲链表的操作
分配块 Segregated Fit 的分配策略就很清晰了:
先从对应的大小类的空闲链表中查找
如果找不到,则到下一个更大的大小类查找
如果都找不到,则扩展堆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void *find_fit (size_t asize) int num = search(asize);unsigned int * bp;while (num < CLASS_SIZE) {while (bp) {if (GET_SIZE(HDRP(bp)) >= asize){return (void *)bp;return NULL ;
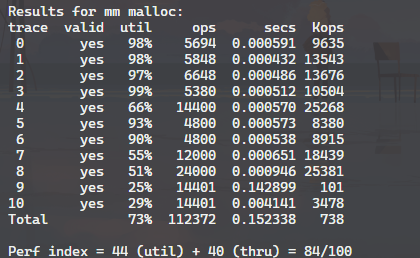
与 Implict Free List 进行对比,发现本方法空间利用率略微降低了,而吞吐量提高了近 50 倍!
总结
CSAPP课本的排版很有意思,比如Implict Free List 花费了大量篇幅讲解,给出了所有代码,而后面的 Segregated Free Lists 却几乎是一笔带过。现在做完了实验才知道,原来是要把这部分放进实验考察,果然读 CSAPP 一定要做实验,两者是相得益彰的。
一堆宏定义与指针写的头皮发麻